在监督式微调之后,RLHF 是一个用于使大型语言模型(LLM)的答案与人类期望对齐的步骤。这个想法是从人类(或人工)反馈中学习偏好,这可以用来减少偏见、审查模型或使它们以更有用的方式行动。它比SFT更复杂,通常被视为可选的。
偏好数据集:这些数据集通常包含几个答案,并附有某种排名,这使得它们比指令数据集更难制作。
近端策略优化
近端策略优化(Proximal Policy Optimization):该算法利用一个奖励模型来预测给定文本是否被人类高度排名。然后使用这个预测来优化SFT模型,基于KL散度的惩罚。
1.TRPO (Trust Region Policy Optimization)
在策略优化的过程中,如果策略更新幅度过大,可能导致智能体行为变得不稳定,甚至导致性能严重下降。因此,需要控制策略更新的幅度,使其在“信任区域”内。


KL 散度的限制

TRPO 的缺点
虽然 KL 散度约束能够限制策略更新幅度,避免策略崩溃,但也带来了一些问题:
- 实现复杂性:
- 求解带约束的优化问题需要使用拉格朗日乘子法或共轭梯度法。
- 需要计算并约束 KL 散度,这涉及二阶优化(Hessian 矩阵),计算代价较高。
- 计算开销大:
- KL 散度的计算需要对策略的所有可能动作概率进行求和,这在高维动作空间中非常耗时。
2.PPO (Proximal Policy Optimization)
PPO 是对 TRPO (Trust Region Policy Optimization) 的改进。TRPO 在目标函数中引入 KL 散度约束,限制新旧策略的差异,保证策略更新的稳定性,但是计算 KL 散度的过程较为复杂,需要二阶优化(如共轭梯度法)
PPO 的核心目标函数



PPO 算法的工作流程
(1) 数据采样
- 从当前策略 $\pi_{\theta_{\text{old}}}$ 中采样状态-动作对 $(s_t, a_t)$。
- 收集对应的奖励 $r_t$ 和下一状态 $s_{t+1}$,计算优势函数 $\hat{A}_t$。
(2) 优化目标函数
- 使用小批量数据 (mini−batch) 对目标函数 $L^{\text{CLIP}}(\theta)$ 进行多次优化。
- 使用一阶优化方法(如 Adam 优化器)更新策略参数 $\theta$。
(3) 重复迭代
- 每次优化完成后,更新策略参数 $\theta$。
- 使用新策略进行下一轮采样,重复以上过程,直到智能体收敛或达到最大训练步数。
直接偏好优化(Direct Preference Optimization,DPO):DPO 通过将其重新定义为分类问题来简化过程。它使用参考模型而不是奖励模型(无需训练),并且只需要一个超参数,使其更稳定、更高效。
一些参考
1.stackLLaMA
StackLLaMA 使用Stack Exchange 数据集 Stack Exchange dataset使用如下打分 score = log2 (1 + upvotes) rounded to the nearest integer, plus 1 if the questioner accepted the answer (we assign a score of −1 if the number of upvotes is negative).
分批训练
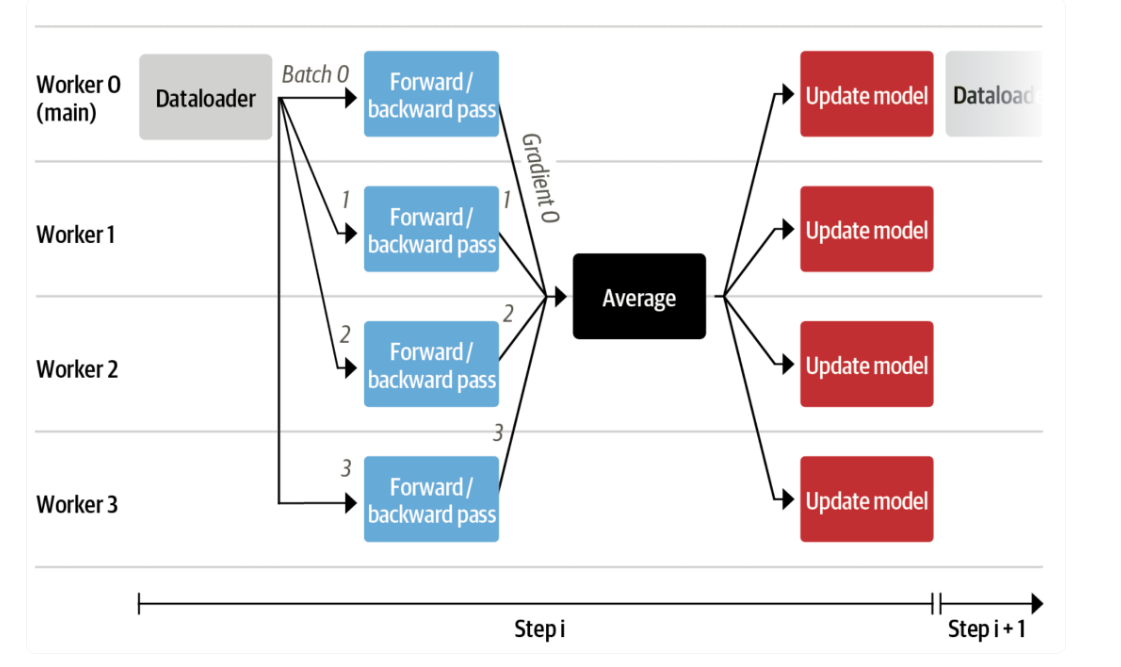
Training
 1. Rollout(采样阶段)
1. Rollout(采样阶段)
- 过程:
- 给定一个 Query(问题/输入),例如 “What is 2x4?”。
- 使用当前语言模型(LM,如 LLaMA)生成一个 Response(回答),例如 “A: 8”。
2. Evaluation(评估阶段)
- 过程:
- 将 Query + Response(问题和回答的拼接) 输入到一个 Reward Model(奖励模型) 中。
- 奖励模型(如 LLaMA-RM)输出一个 Reward(奖励值),例如 1.0,表示生成回答的质量得分。
3. Optimization(优化阶段)
- 过程:
- 奖励信号驱动优化:
- 使用奖励值(Reward)指导语言模型的优化,通过策略梯度方法(如 PPO,Proximal Policy Optimization)。
- 对比损失函数:
- 计算当前语言模型(LM)的生成结果和参考模型(Reference Model,通常是初始未优化模型)的对比损失。
- 对比的目标包括:
- log-probs(对数概率):评估生成的可能性。
- KL-div(KL散度):约束当前模型的输出与参考模型输出不要偏离太远,防止模型过度拟合奖励信号。
- 更新模型参数:
- 综合奖励值和 KL 散度,调整语言模型的参数,让其更倾向于生成高奖励的回答,同时避免生成与参考模型偏差过大的回答。
- 奖励信号驱动优化:
关键概念:
-
Reward Model(奖励模型):
- 奖励模型由人类标注的数据训练而成,能够为模型生成的回答打分,用作优化的信号。
- PPO(Proximal Policy Optimization):
- 一种强化学习算法,通过引入 KL 散度约束,稳定地更新策略,防止模型在优化过程中出现严重退化(如生成模式崩塌)。
- KL散度(KL-divergence):
- 用来衡量当前模型与参考模型输出分布的差异,作为正则化项,避免模型过度偏向奖励信号。